

תוכן עניינים
אמ:לק - משקל מודל השפה נקבע מכמות הפרמטרים שהוא מכיל. כל פרמטר מיוצג מספרית בצורה מסוימת. טכניקת קוונטיזציה מאפשרת להריץ מודל גדולים בצורה חסכונית יותר. בואו נדבר על זה.
בעידן שלנו, מונחים כמו ״זיכרון״ של מעבד (זה ששייך למחשב עצמו) או ״זיכרון״ של מעבד-גרפי (זה ששייך לכרטיס המסך) - נזרקים לחלל האוויר כלאחר יד.
כולנו שומעים על מעבדים עם 4 ליבות, 8 ליבות, על כרטיסי מסך של NVIDIA עם אלפי ליבות, אנו רואים את המניה של אנבידיה מרקיעה שחקים אבל האם אנחנו מבינים באמת מדוע? ואחרי כל זה, כמה זיכרון אנחנו צריכים במחשב שלנו כדי להריץ מודל שפה?
זוכרים מה זה זיכרון?
אמנם אנחנו משתמשים בתוכנה של המחשבים והטלפונים החכמים שלנו, אבל הכל רץ בסוף בזכות החומרה עצמה. אין מחשב שיכול לרוץ מבלי החומרה שלו וכמו שאנחנו כבני אדם כנראה לא נצליח לבצע משימות אם לא נזכור כלום, כך גם המחשב צריך זיכרון כדי לבצע את המשימות השוטפות שלו.
למחשב יש מספר סוגים של זיכרון:
- כונן קשיח - המידע שלנו שנשמר על כונן קשיח, Hard Disk, כזה שגם אם יש הפסקת חשמל שום דבר לא נמחק.
זיכרון נדיף (RAM) - כאן מדובר בזיכרון שדרוש למחשב כדי לטעון תוכנות ולהריץ אותן. דמיינו שאתם לוחצים על הדפדפן במחשב או בטלפון שלכם (שהוא גם סוג של מחשב): הורדתם אפליקציה של דפדפן, הקוד נשמר על המכשיר עצמו. אבל! כאשר אתם לוחצים על הדפדפן כדי להשתמש בו, המחשב צריך לקחת את הקוד של הדפדפן, לטעון אותו לזיכרון, להתחיל להריץ את הקוד בפועל: לפתוח את הדפדפן, לטעון את הממשק שלו, לאפשר את הלוגיקה שלו - גלישה באינטרנט וכדומה. כל זה מתאפשר בגלל שהמחשב טוען את הקוד אל תוך הזיכרון. אם תהיה הפסקת חשמל, כל מה שנטען לזיכרון פשוט יאבד, מהסיבה הפשוטה שמדובר בזיכרון ״נדיף״, כזה שפשוט ״מתנדף״ לו. הוא לא נשאר לנצח כמו זיכרון של כונן קשיח.
זיכרון RAM יכול להיות כרטיס פיזי במחשב שאליו ייגש המעבד, או גם זיכרון RAM שמיועד לעיבוד וידאו במעבד-הגרפי (VideoRAM = vRAM).


ויש גם את ליבת העניין
למעבד שלנו במחשב יש כיום מספר ליבות. כל ליבה יכולה לנהל תהליך, כך שאם למעבד יש למשל 4 ליבות, הוא יכול לנהל 4 תהליכים במקביל. ומה אם יש לו 8 ליבות? אז כבר אפשרי לנהל 8 תהליכים במקביל! כפול! נשמע הרבה נכון? אבל צריך לזכור שהתפקיד של מעבד הוא לעבוד בצורה טורית, סדרתית. פקודה אחר פקודה. הוא לא נועד כדי לעבוד בצורה מקבילית - קרי: לבצע מספר פעולות במקביל בו-זמנית.
דמיינו שאתם בחדר כושר מרימים משקולות. מה המשקל המירבי שתוכלו להרים מבלי לקרוס? 10 קילו, 20 קילו, אפילו 90 קילו, אבל האם תוכלו להרים טון? כנראה שלא.
אותו הדבר אצל המעבד. הוא יכול לטעון קוד שכדי להריץ אותו דרוש הרבה מקום. נניח שיש תוכנה שיש לה צורך בהמון משאבי מחשוב כדי לעבוד. למשל, כדי לעבוד תקין נניח שהיא צריכה 10 גיגה של זיכרון נדיף, RAM. אם המחשב שלנו בנוי בתצורה שיש לו רק 8 גיגה של RAM, הוא פשוט לא יצליח לבצע את המשימה הזו. זה כמו להרים משקל כבד הרבה יותר ממה שאנחנו מסוגלים.
בעולם הרצת מודלים גדולים של שפה הדבר מקבל משנה תוקף: מודל שפה ״קטן״ שיש לו 7 מיליארד פרמטרים, מיוצג ללא כיווץ כלשהו על ידי 7 מיליארד מספרים. כל מספר מיוצג על ידי 4 בתים (בייטים), כך שדרושים 28 מיליארד בתים כדי לטעון מודל של 7 מיליארד פרמטרים. כמה זה 28 מיליארד פרמטרים? 28 גיגה בייט.
ומה אם רוצים לעבוד עם מודל רציני יותר של 70 מיליארד? אז כבר נצטרך זיכרון שמסוגל לעבוד עם 280 מיליארד בתים, שזה 280 גיגה. ואם אין לנו כזה במחשב - פשוט לא נוכל להריץ אותו מקומית ונצטרך לשלם על קריאות לספק חיצוני שנעבוד דרכו, או לשלם על השכרת מחשוב יקר יותר במשאבי ענן.
קוונטיזציה רבותיי!! (רגע, מה?!)
בגלל הסיפור הזה קמה לה טכניקה מאוד מעניינת של קוונטיזציה: לוקחים את הרשת שעליה אומן המודל, זו ששוקלת כמה מיליארדים, ומכווצים אותה באמצעות טכניקות שונות כמו הסרת פרמטרים משכבות מסוימות, בצורה שתפגע כמה שפחות בדיוק של המודל. זה מה שמכונה Pruning.
ולא רק זה. מה אם היינו מצליחים לייצג מספרים באמצעות 2 בתים במקום 4? אז כדי להריץ מודל של 70 מיליארד פרמטרים נצטרך חצי מהכמות: רק 140 גיגה במקום 280 גיגה!
איך קורה הקסם הזה? זו תורה שלמה של קוונטיזציה שהרעיון המרכזי הוא לייצג מידע בדרך אחרת. במקום לייצג מספר באמצעות ״נקודה צפה״ (Floating Point) שאורכה 32 סיביות (Floating Point 32, fp32), נייצג אותו באמצעות ״נקודה צפה״ שאורכה 16 סיביות (Floating Point 16, fp16), או אפילו באמצעות מספר שאורכו 8 סיביות בלבד (INT8).
כאשר ״מכווצים״ מידע מסתכנים באיבוד הדיוק של המודל. לכן הדרך הכי טובה היא להשוות בין תוצאות ה-Prompt בכל אחת מהדרכים. כמו תמיד, לא תהיה אמת אחת וכנראה שלפעמים נצטרך להשתמש בייצוגים שונים, פעם ב-32 ופעם ב-16 ופעם ב-8, הכל שאלה של כמה נרצה לחסוך.
וחזרה לזיכרון (זוכרים?)
כשאנחנו בונים מחשב, אנחנו רוכשים זיכרון נדיף RAM וכאמור, מדובר במשקל המקסימלי שהמחשב יוכל לשאת כדי לבצע פעולה מסוימת. לצד זאת, כיום בעידן ה-AI אנחנו עדים גם לעליית כרטיסי המסך היוקרתיים שמכילים vRAM במעבד הגרפי של כרטיס המסך. היתרון של המעבד הגרפי הוא ביצוע פעולות במקביל, בו-זמנית, ולא אחת אחרי השנייה. למה זה משמעותי? גם כי זה חוסך זמן אבל גם כי מדובר בטכניקה מאוד משמעותית כדי לאמן מודלים שיהיו כלליים ככל הניתן (Generalized). פירוש הדבר: מודלים שרואים ייצוג של מידע בבת אחת בתהליך האימון, ידעו ל״נבא״ טוב יותר גם על מידע שמעולם לא היה בסט האימון שלהם. במהלך האימון, המידע מחולק למקטעים ונטען לזיכרון בזה אחר זה, בתצורה של Batches, קבוצות. ככל שניתן לטעון ״קבוצות״ של מידע בתהליך האימון, כך זיהוי הדפוסים במספרים (שזו משמעות אימון מודל) מתבצע טוב יותר, כי הוא מחפש דפוס בקבוצה של מידע ולא רק בערכים בודדים.
כיום אנו יכולים למצוא בכרטיס המסך היוקרתי של NVIDIA, הלא הוא ה-RTX 4090, כ-16 אלף ליבות(!) וכ-24 גיגה vRAM! נכון, תגידו בטח: רגע רגע אבל אמרת שצריך 140 גיגה כדי להריץ מודל של 70 מיליארד פרמטרים מקומית על המחשב!
נכון מאוד! לכן החלוקה ב-RAM בין המעבד למעבד-הגרפי היא קריטית. אם המחשב שלנו יהיה עם 192 גיגה זיכרון RAM ועוד 24 vRAM, זה אומר שבהחלט נצליח להריץ לוקאלית את המודל של ה-70 מיליארד אם נשתמש בכזה שמיוצג על ידי 2 בתים (fp16)! למה זה מעניין? לענייני אבטחת מידע, פרטיות, ביטחון, חיסכון בעלויות ושימוש בספקים חיצוניים.
הזיכרון הוא המפתח פה. ככל שנבין מה החומרה הדרושה כדי להריץ מודלים מקומית, כך נצליח ליצור דברים מדהימים יותר. למשל: הרזברי פיי 5, שהזיכרון שלו בגודל 8 גיגה RAM בלבד, לא יוכל להריץ מודלים גדולים, אבל הוא כן יוכל להריץ מודלים קטנים. מי שמבין את החישוב שהסברתי כאן, גם ידע להבין בדיוק איזה מודלים ניתן להריץ ואיזה לא.
ונסיים עם טיפ מעשי
באתר HuggingFace יש המון מודלים של שפה שפתוחים לשימוש בחינם. בכל מודל ניתן למצוא את מספר הפרמטרים שהוא מכיל וכך גם לחשב לבד האם אנו יכולים להריץ אותו או לא. למשל בעמוד של מודל השפה Command-R-Plus של Cohere המדהימים ניתן לראות:
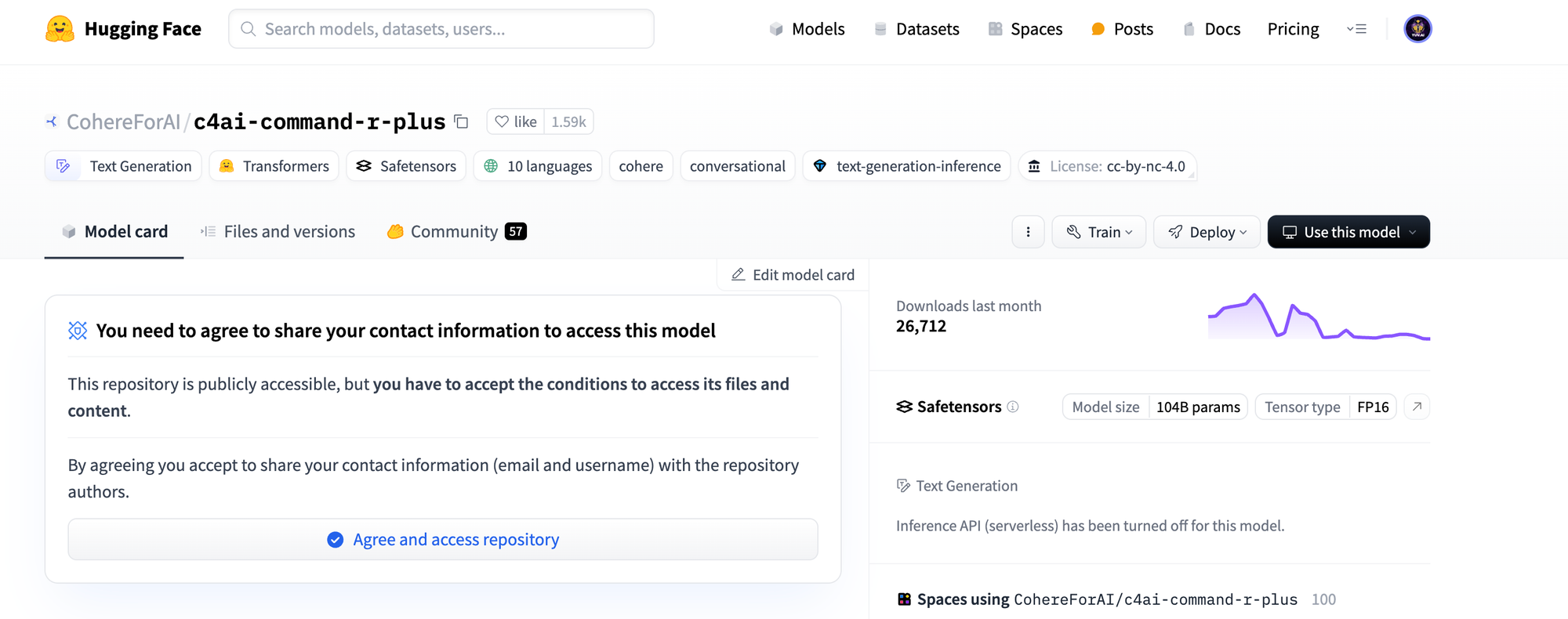
מצד ימין ממש מצוין כמה פרמטרים (104 מיליארד) וסוג הייצוג (FP16):
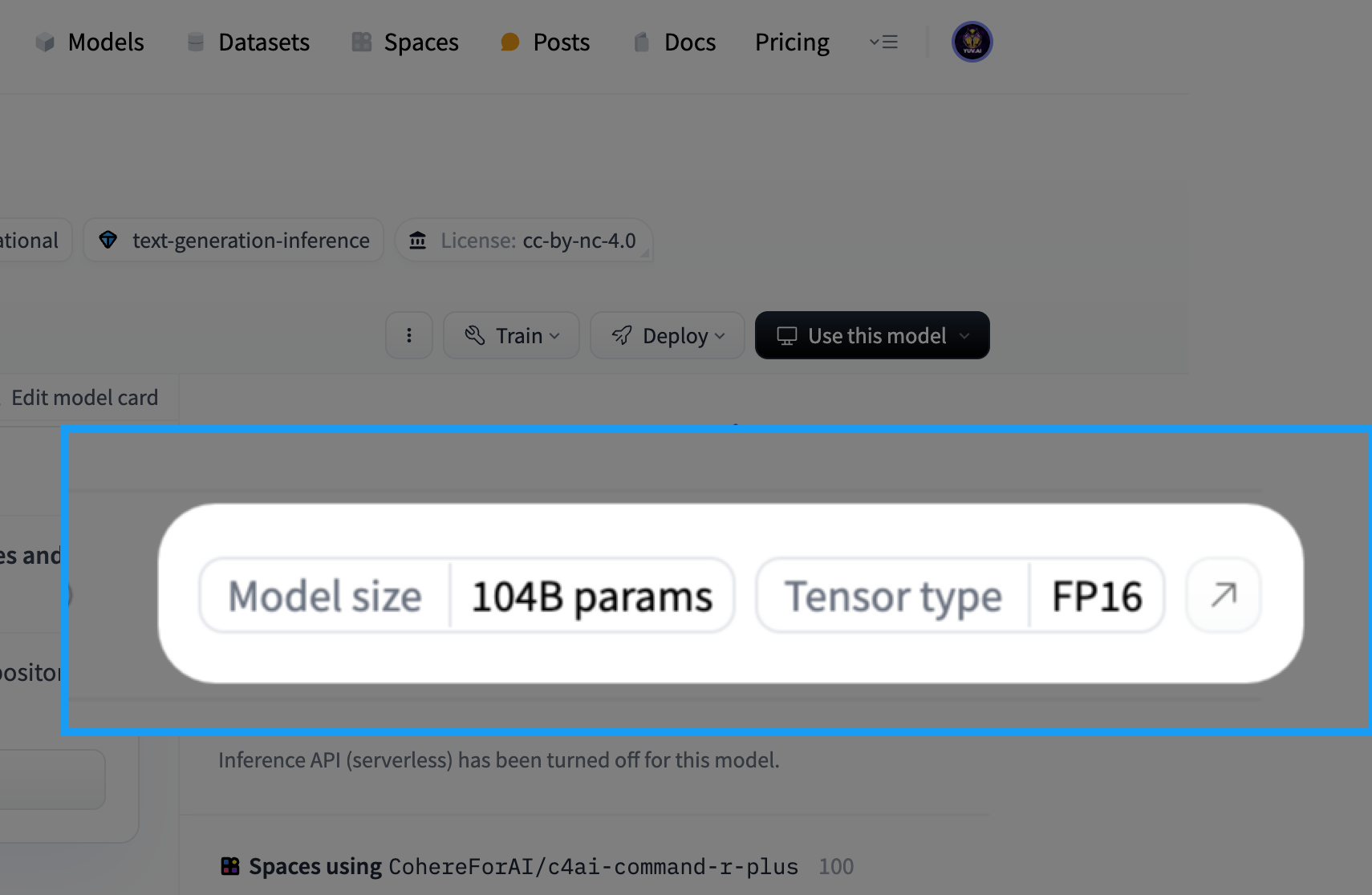
כדי שנבין, 104 מיליארד בייצוג של FP16 זה אומר 208 גיגה. זה מה שנדרש כדי להריץ את המודל של קוהיר מקומית. מבינים עכשיו את הסוד?
ויש גם אתר ממש מדליק שאפשר להזין בו את הערכים של הרשת והוא לבד מחשב כמה vRAM אנחנו נצטרך כדי להריץ את המודל, ממש צריך לבחור את סוג הייצוג של המודל ואת הערכים השונים ומקבלים את כל המידע:
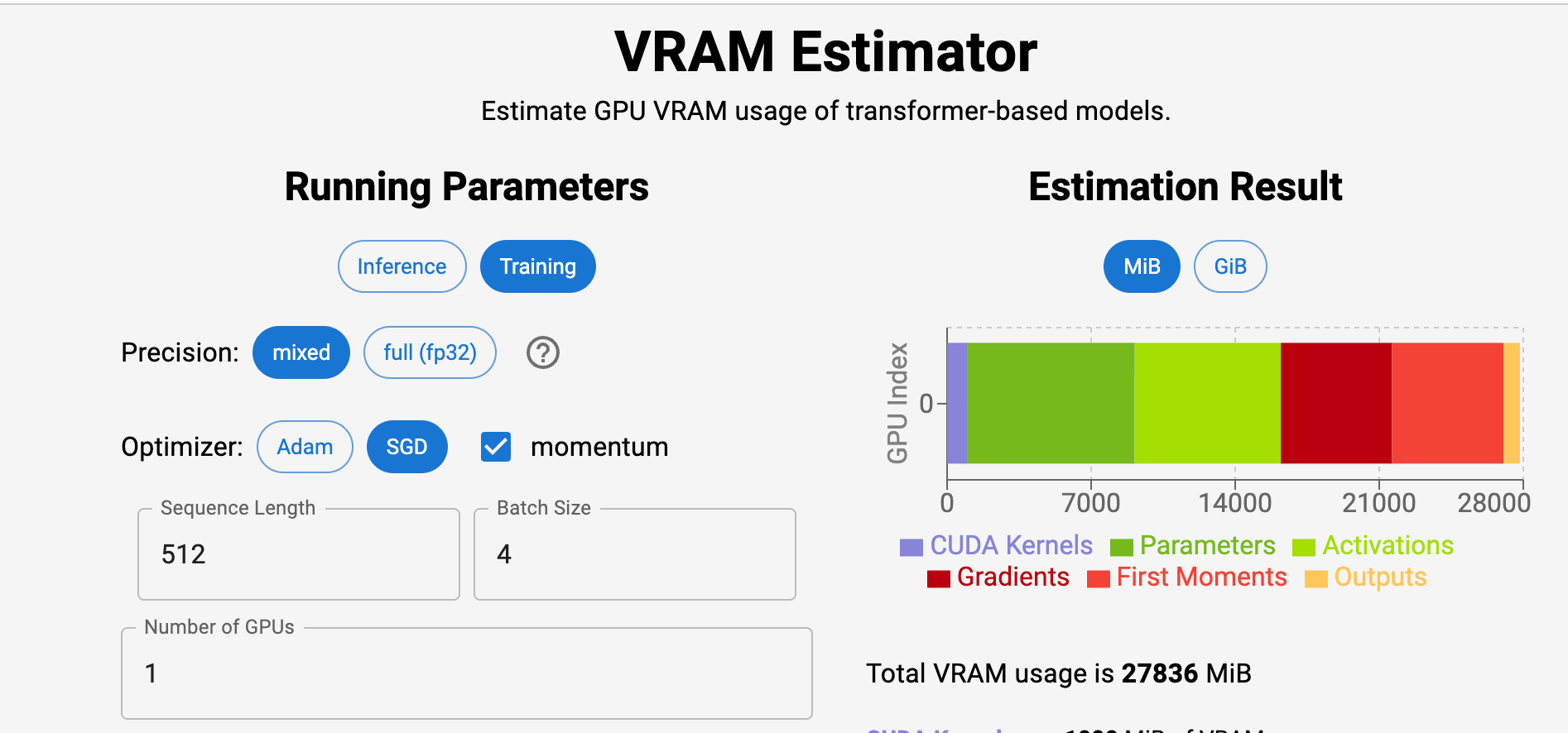
קישור לאתר:
אשמח לקרוא את התובנות שלכם בתגובות.
תודה שקראתם ומקווה שקיבלתם ערך.
נתראה במאמרים הבאים.
יובל
נ.ב - זוכרים שהשקתי את קורס האוטומציות שלי? בואו לקרוא עליו:
 Yuval Avidani
Yuval Avidani