

תוכן עניינים
אמ:לק
קיימים מודלים מגוונים של למידת מכונה שמסוגלים לעבד שפה ולבצע משימות רבות הקשורות לניתוח שפה, כגון: השלמת טקסטים, ניהול שיח איתנו, ניתוח סנטימנט ועוד. הקסם הזה מתאפשר על ידי אימון של מודל שפה גדול (LLM). המודלים שכבשו את העולם הם אלה שמבוססים על ארכיטקטורה (תשתית) שנקראת Transformers ומכילה יכולת לתת תשומת לב והקשר למשפטים שלנו.
סקרנות היא המנוע
אחד הדברים שהכי מרתקים אותי זה להבין דברים מתחת למכסה המנוע, מורכבים ככל שיהיו. לא תמיד זה קל. לא תמיד זה מצליח עד הסוף. אבל עצם הסקרנות לא נותנת לי מנוח. גם בכל מה שקשור ליכולת של בינה מלאכותית לדבר אלינו, איתנו, במילים, בקול. איך זה קורה?
השאלה הזו מעוררת אותי לחקור בלי סוף. בפוסט הזה אני אשתף חלק מהמחקר שלי, שקשור לעיבוד שפה טבעית (NLP), שזה בעצם היכולת של בינה מלאכותית להבין את הטקסט שלנו ולהשיב לנו, כבני אנוש ממש.
בקטנה על LLMs
מודלים גדולים של שפה, Large Language Models = LLMs, מסוגלים לקבל רצף של טקסט ולהשיב לנו באמצעות טקסט. העוצמה האמיתית שלהם נובעת מכך שהם מסוגלים לקבל כמות עצומה של מידע, ללמוד אותה ולהשיב לנו בהתאם על בסיס מאגר הידע שלה. לא רק על שאלות שקשורות לחומר אותו הם למדו במהלך האימון, אלא אפילו שאלות שלא קשורות למה שהיה באימון - גם על שאלות כאלה הם מסוגלים להשיב.
והאמת ש-ChatGPT, שמאפשר לנו צ'אט עם מודל GPT של OpenAI, הוא מודל גנרטיבי. דהיינו: מודל שיוצר טקסט חדש על בסיס הידע שיש לו, יחד עם היכולת שלו לקבל מאיתנו פרומפט (טקסט), להבין את מה שהזנו, להבין את ההקשר ולהשיב לנו בהתאם.
אבל יש בעולם מודלים נוספים. לא תמיד אנחנו רוצים מודלים שיכולים להתכתב איתנו. בהרבה מקרים בעולם האמיתי רוצים לעבוד עם מודלים גדולים של שפה גם למטרות אחרות כמו סיווג מידע, חלוקה שלו לקטגוריות ועוד.
על GPT של OpenAI ו-BERT של גוגל
כך למשל, יש מודל בשם BERT של גוגל, שגם הוא נשען על ארכיטקטורת הטרנזפורמרים וגם הוא מודל שפה גדול, אך הוא בנוי קצת אחרת ומשמש למטרות אחרות לגמרי. בניגוד ל-GPT, התפקיד שלו הוא לא לייצר טקסט חדש, אלא בעיקר להבין טקסט קיים. אם GPT מנבא את המילה הבאה על בסיס טקסט קודם, BERT פועל שונה, הוא משיב לשאלות מתוך הבנה של הטקסט הקיים תוך שהוא מסתכל על הטקסט בצורה דו כיוונית: לא רק המילים שקדמו, אלא גם המילים שבאו לאחר מכן.
אם נזין שאלה כגון: ״מה המקום הכי יפה ב״ למודל של GPT עצמו (לא ChatGPT), נתחיל לקבל רצף של אפשרויות, כגון:
מה המקום הכי יפה בכדור הארץ
מה המקום הכי יפה בירושלים
מה המקום הכי יפה בישראל
וכך הלאה. השלמה של משפטים. למה? כי המודל מסתכל על מה שכתבנו ומנסה לנבא את המילה הבאה. זה מודל חד-כיווני.
מנגד, BERT מבין דברים בצורה אחרת. הוא יבין לעומק טקסט שנזין אליו והתפקיד שלו לא יהיה להשלים לנו משפטים או לתת לנו תשובה, אלא לתת לנו מענה על תוכן שקשור לטקסט. בעומק. הוא בעצם מסתכל על כל הטקסט, מבין, ומסוגל להשיב על ניתוח שלו.
גם GPT וגם BERT בנויים על ארכיטקטורת טרנזפורמרים. אך בעוד ש-GPT משתמש במפענח (Decoder) בלבד כדי לייצר טקסט חדש, BERT משתמש במקודד (Encoder) בלבד, שתפקידו בעצם לקודד טקסט בצורה שיש לה משמעות מסוימת בסוף. זה מקור השוני, GPT משתמש במפענח, BERT משתמש במקודד, שניהם משתמשים בטרנזפורמרים.
מה זה טרנזפורמר?
רגע לפני שאשיב על זה אציין בתמצות שבעולם למידת המכונה יש לנו קטגוריה של ״למידה עמוקה״, בה מבצעים שימוש נרחב ברשתות עצביות (רשתות ״נוירונים״) כדי לאמן מודלים על כמות אדירה של טקסטים, תוך שמצליחים להגיע לביצועים מרשימים מאוד.
רשת נוירונים מדמה את המוח במידת מה. במוח יש לנו נוירונים ועצבים שמקשרים ביניהם. הנוירון יכול לפעול או לא. כך הוא מעביר מידע, במוח שלנו יש כמות אדירה של נוירונים והחיבור ביניהם הוא הקסם האמיתי שגורם למוח שלנו להפעיל את הגוף שלנו ואת שאר הכלים שלו. מה רבו מעשיך השם!
אז טרנזפורמרים בעצם באו לתת מענה לבעיה של רשתות נוירונים, בהן מזינים מידע, מאמנים מודל, המידע מוזן בין שכבות שונות של נוירונים עד שמקבלים בסוף תחזית כלשהי. איפה הבעיה? שאין הקשר בהכרח. צריך הקשר. הבנה עמוקה. לא רק ניבוי.
טרנזפורמרים הוצגו ע״י גוגל ב-2017 במאמר המפורסם שלהם Attention is all you need, ספק ידעו את ההשפעה שתהיה להם על העולם, ובמאמר הם נותנים מענה לבעיה הזו באמצעות הצגה של שכבות תשומת לב וקידוד של המיקום. האמת שיש עומק נוסף לזה אבל זה הכי כללי והכי פחות מסובך.
איך זה עובד?
אנחנו מזינים טקסט למודל.
הטקסט נחתך לאסימונים.
האסימונים מומרים לייצוג מספרי באמצעות טכניקת קידוד.
הקידוד הופך לרשימה ארוכה של מספרים.
בנוסף נוצרת רשימה נוספת של ״מסיכת תשומת לב״ שתפקידה לעזור למודל להבין לאיזה מילים לתת דגש ולאיזה לא.
מתחיל תהליך חישוב מורכב מתמטית (אם כי לא מדי), שבו מתבצע חישוב ״תשומת לב״ ו״הקשרים״. בהסתמך על משוואות מתמטיות, המכונה מנסה למצוא דפוסים ברשימות המספרים שהוזנו אליה וכך בעצם ״מבינה״ איזה מספרים קשורים לאיזה, מה קרוב למה, מה רחוק ממה. כדי להבין זה כמו שהמודל מנסה ללמוד מה זה חתול, כלב, איך נראית הספרה 1 ואיך 8 וכך הלאה.
אז התהליך עצמו מקצה לקצה יכול להשמע מאוד מורכב ואכן יש כאן פירוט רב שאפשר לדבר עליו, אבל אני רוצה לתת לכם הצצה מתחת למכסה המנוע של איך נראה התהליך הזה של הפיכת טקסט לייצוג מספרי לטובת אימון מודל. זה AI אמיתי גבירותיי ורבותיי.
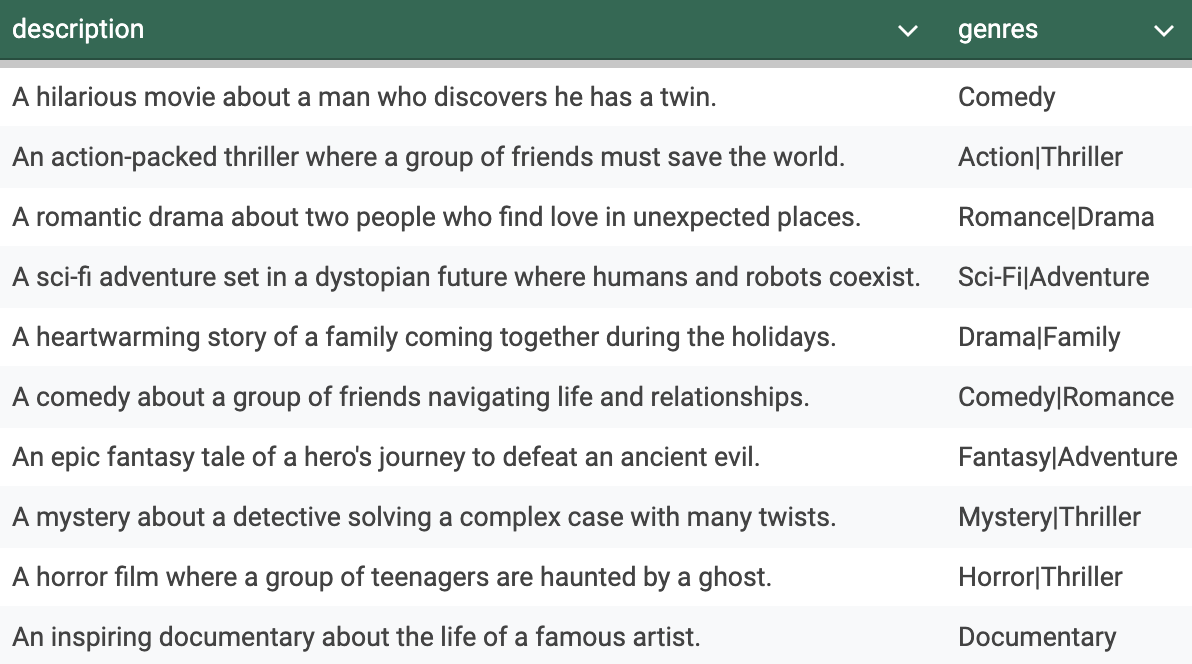
מתיאור של סרטים למודל שיודע לסווג ז'אנרים
כדי להמחיש זאת, ביקשתי מ-ChatGPT ליצור לי קובץ פשוט עם 2 עמודות: תיאור של סרט ולאיזה ז'אנר הוא מתאים. סרט אחד יכול להתאים למספר ז'אנרים (קומדיה, דרמה, אקשן וכדומה).
כך זה נראה:
לטובת ההמחשה אני משתמש כאן בחבילת Scikit-Learn שמשמשת ללמידת מכונה, Transformers של HuggingFace ו-TensorFlow.
# Load libraries
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MultiLabelBinarizer
from transformers import XLMRobertaTokenizer, TFXLMRobertaForSequenceClassification
import tensorflow as tf
לאחר מכן טענתי את הקובץ שיצרתי:
# Load and preprocess data
data = pd.read_csv("./movies_data.csv")
בשלב הזה הפכתי את עמודת תיאור הסרטים לרשימה של משפטים:
['A comedy about a group of friends navigating life and relationships.'
'A romantic drama about two people who find love in unexpected places.'
"An epic fantasy tale of a hero's journey to defeat an ancient evil."
'An action-packed thriller where a group of friends must save the world.'
'A heartwarming story of a family coming together during the holidays.'
'A mystery about a detective solving a complex case with many twists.'
'A sci-fi adventure set in a dystopian future where humans and robots coexist.'
'A hilarious movie about a man who discovers he has a twin.']
טוקניזציה (רגע, מה?)
ועכשיו מתחיל החלק המעניין. כדי שמודל יוכל לקבל את המידע לטובת אימון, אנחנו צריכים להמיר אותו לרשימה ארוכה של מספרים. השלב הראשון נקרא טוקניזציה (Tokenization), שזו מילה גדולה ל״חיתוך״ של המילים לאסימונים, חתיכות קטנות. כך למשל, המשפט הראשון ברשימה:
A comedy about a group of friends navigating life and relationships.
הופך לאחר טוקניזציה לדבר היפה הבא:
['', '▁A', '▁comedy', '▁about', '▁a', '▁group', '▁of', '▁friends', '▁naviga', 'ting', '▁life', '▁and', '▁relationships', '.', '', '', '', '', '', '', '', '']
כן כן. יפה נכון? וברצינות, שימו לב. בהתחלה יש לנו אסימון מיוחד שמסמל התחלה, בסוף יש לנו אסימון מיוחד שמסמל - סוף. באמצע יש לנו את הרשימה של האסימונים שנוצרה לנו על ידי הטוקנייזר. איך זה קורה, כמה זה מורכב, אפשר לדבר במשך שעות אבל אין טוב יותר מהסרטון של אנדרי קפארתי הגאון כדי להבין:
אחרי שלב הטוקניזציה, אנחנו משתמשים במקודד (Encoder) שהופך את הטוקנים שלנו לרשימה מספרים. כל טוקן מקבל ייצוג, וכך המשפט שלנו הופך להיות:
[0, 62, 180327, 1672, 10, 21115, 111, 23902, 56136, 1916, 6897, 136, 151618, 5, 2, 1, 1, 1, 1, 1, 1, 1]
כן כן. המשפט נחתך לטוקנים, כל טוקן הפך לייצוג מספרי. וזה לא נעצר כאן. אנחנו עובדים עם טרנזפורמרים זוכרים? אז במקרה הזה אנחנו צריכים להוסיף עוד רשימה שנקראת ״מסיכת תשומת לב״ ובעצם עוזרת למודל להבין לאיזה מילים יש משמעות ואיזה מילים הן מילות ללא משמעות מיוחדת כמו מילות קישור וכדומה. כך מסיכת תשומת הלב של המשפט שלנו נראית:
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0]
כל מקום שיש בו את הערך 0 אומר למודל ״תתעלם מהמילה שמקושרת אליה״, מנגד כל מקום שיש בו את הערך 1 אומר למודל ״למילה הזו אתה צריך להתייחס בתהליך האימון״.
אמבדינגז (שו?!)
מכאן, כל ערך מספרי מומר באמצעות טכניקה נוספת הקרויה Embeddings (אמבדינגז) לרשימה ארוכה מאוד של מספרים. כמה ארוכה? ב-BERT כל טוקן מיוצג על ידי רשימה באורך של 768 מספרים, ב-OpenAI כל טוקן מיוצג על ידי רשימה באורך של 1536 מספרים. כל מספר הוא בעצם מימד בפני עצמו. דמיינו שיש לכם גרף של ציר, יש X ויש Y. זה 2 מימדים. כשאנחנו מדברים על 768 מימדים אנחנו מדברים על מימדים בצורה שאנחנו לא מסוגלים להבין כבני אדם, אבל זה פלא. כל טוקן הופך לרשימה אדירה, ולרשימה האדירה הזו יש משמעות. טוקנים עם משמעות קרובה, יקבלו רשימת מספרים ענקית שיש קשר ביניהם. נניח ש״שמח״ מיוצג על ידי רשימה של 0.3, 0.1, 0.8, אז בעולם של אמבדינגז, הטוקן ״מאושר״ אמור להיות מאוד קרוב בערכים שלו, כי המשמעות דומה. משהו בסגנון של 0.2,0.09,0.76. לא מספרי מדויקים אבל קרובים.
הטוקנים מומרים למספרים, וקטורים, שיש להם משמעות. זה מדהים. כי בסוף כל טקסט הופך לווקטורים בעלי משמעות ואז כאשר אנו מזינים טקסט למודל, גם הוא הופך שוב לווקטורים ומתבצע חישוב (או השוואה) בין הווקטורים של הטקסט שאנו מזינים לבין הווקטורים של המידע שהמודל אומן עליו.
טכניקה מפורסמת מאוד נקראת ״חיפוש סמנטי״ או ״חיפוש קירבה״, משתמשים בה ב-RAG (פתרון לשליפת מידע שנשמר בבסיס נתונים וקטורי). אין כאן המקום להרחיב על כך, אולי בהמשך אם תגיבו שמעוניינים בכך.
ואם מסקרן אתכם איך נראה הווקטור של המשפט שלנו מלמעלה? אז בבקשה, ייצוג חלקי שלו:
[[[ 0.08959979 0.04733777 0.03706381 ... -0.08934632 0.08721507
0.00758183]
[-0.0350717 -0.05650188 -0.04258913 ... -0.06681602 0.02146915
0.3230402 ]
[-0.02987211 -0.01256225 -0.00250898 ... 0.11090799 0.00220406
0.22726344]
אז כל הדבר היפה הזה מוזן לרשת נוירונים, או במקרה שלנו לטרנזפורמר. זה הטקסט שהמודל מתאמן עליו. אבל! זוכרים שיש לנו את התיוג? הדאטה שלנו הכיל גם תיאור וגם תיוג, זה נקרא למידת מכונה ״מפוקחת״ או ״מושגחת״ או ״מתויגת״ (Supervised Learning), כי יש לנו גם את התוצאות שאנחנו מצפים מהמודל לתת לנו. כמו במקרה של הטבלה שלנו, סיפקנו תיאור וגם תיוג. המודל יתאמן על הדאטה שלנו וכאשר ניתן לו תיאור של סרט אחר, שלא מופיע ברשימה, הוא אמור לתת לנו קטגוריות מתאימות בעצמו.
האיכות היא זו שקובעת
אמור - כי כמו שאתם בטח מבינים, איכות המודל תלויה באיכות הדאטה. דאטה מגוון רחב ואיכותי יוביל למודל מעולה. לא גודל הדאטה הוא העיקר אלא דווקא האיכות שלו. בטכניקות Fine Tune (כמו בעבודה עם BERT במקרה הזה), בהן אנו מוסיפים דאטה סט קטן למודל בסיס גדול, הוכח שאיכות הדאטה חשובה יותר מגודל הדאטה סט, זאת בניגוד לקולות רווחים, גם בקהילות למידת מכונה שלא אזכיר כאן, אך האמת הפוכה. פרסמתי כאן לאחרונה את דבריו של קפראתי.
חזרה לענייננו, יש לנו גם תגיות. נזכיר שהמשפט שלקחנו לדוגמא היה:
A comedy about a group of friends navigating life and relationships.
התיוג שלו הוא:
Comedy|Romance
ומה מסתבר שקורה בתהליך אימון? במקרה כמו שלנו, שבו אנחנו רוצים יותר מתוצאה אחת (כי סרט יכול להתאים ליותר מז'אנר אחד), יש לנו כלים שנקראים Binarizer שבעצם עוברים על כל התיוג, יוצרים רשימה של כל האפשרויות (רשימת חד-חד-ערכית, כל ערך מופיע פעם אחת), והופכת את הרשימה הזו לרשימה מספרים בעלת 0 ו-1 בלבד.
כך כל קטגוריה הופכת לעמודה. דמיינו שיש 10 עמודות עם 10 קטגוריות. קטגוריה בכל כותרת. בכל פעם שהקטגוריה מתאימה לתיאור של הסרט, יופיע 1, אחרת יופיע 0.
נניח שאנחנו מדברים על קומדיה ורומנטיקה, אז עבור קומדיה יופיע המספר 1 בטבלה, כנ״ל עבור רומנטיקה ואילו עבור כל השאר הערך יהיה 0. ככה התגיות מיוצגות בקוד:
array([list(['Comedy']), list(['Action', 'Thriller']),
list(['Romance', 'Drama']), list(['Sci-Fi', 'Adventure']),
list(['Drama', 'Family']), list(['Comedy', 'Romance']),
list(['Fantasy', 'Adventure']), list(['Mystery', 'Thriller']),
list(['Horror', 'Thriller']), list(['Documentary'])], dtype=object)
מזה המודל מחלץ את כל הערכים והופך אותם לרשימה אחת בלבד שנראית כך:
array([[0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1],
[0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1],
[0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0]])
נראה מלחיץ נכון? אבל לא באמת, הרעיון הוא שיש כותרת מעל הטבלה הזו. כל עמודה היא קטגוריה. במקרה שלנו למשל, נמחיש זאת כך:
אימה, אלימות, מתח, דרמה, קומדיה, רומנטיקה, מדע בדיוני, אנימציה, ילדים, מבוגרים
[0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0]
כל קטגוריה משוייכת לספרה ברשימה כך ש-1 ״דלוק״ עבור קומדיה וגם עבור רומנטיקה. זו מסיכת תשומת הלב. ממסכת את כל הערכים הלא רלוונטיים, ואומרת למודל - שים לב לתוצאה המספרית, כאשר התיאור הוא X , אתה צריך שהתוצאה שלך תהיה 1 ו-1 במיקומים האלה (זה ה-Y, הפלט).
מעבר לכך יש תהליכים נוספים, מפצלים את הדאטה שלנו, חלק לאימון, חלק לבדיקות תקינות, בוחרים את הגדרות האימון ולבסוף בוחנים את המודל ומתקנים לפי הצורך. כל שלב כזה דורש מאמר כשלעצמו.
אשמח לקרוא בתגובות אם התנסיתם בתהליך כזה, אם עבדתם עם BERT, אם חידשתי לכם פה משהו וגם אם לא. עד אז מקווה שקיבלתם ערך ונתראה בפוסטים הבאים.
מזכיר לכם שנותרו עדיין מקומות בכנס על אף שהרוב אזל, גם אתם יכולים לשריין כסא לכנס שלי ב-17.6. כל הפרטים פה:

תודה שקראתם (גם אם לא החזקתם)!
יובל